

ChatGPT, Midjourney, and Claude AI are taking the world by storm. Do you know what’s the common thing between all of these technologies?
They are all based on the magic of Machine Learning! So, what is this “machine learning” concept? and how does it work?
This article will answer all your burning questions.
What is Machine Learning?
Machine learning is a subfield of computer science and artificial intelligence (AI) that gives computers the ability to learn using data, without being specifically programmed.
Machine learning algorithms train computers using data inputs, and do not explicitly use straightforward algorithms to directly manipulate data, as is the case in traditional computer science algorithms. Machine learning algorithms use inputs in the form of data to output values within a specific range of data.
For example, facial recognition technology uses machine learning to give an approximate identity to each face based on similarities between the face and a previous collection of images of the same face in different situations. This also applies in the field of image search, that allows you to search for images similar to a certain image, or searching for something on the web using an image instead of text.
Optical character recognition (OCR) also uses machine learning to transform text images into text.
Recommendation engines use machine learning to tell users what movies or TV shows they can watch next, based on what they've already watched.
In this article, we'll take a look at some of the most common machine learning methods and algorithms.

Machine Learning Using Supervised Learning
Supervised learning is a range of machine learning algorithms that learn from a set of training data that has been labeled with the correct answer.
The algorithm first builds a model of the training data and then uses the model to predict the correct answer for new data. Supervised learning algorithms essentially compare their actual output with the ready and correct outputs to find errors, and modify the model accordingly.
For example, a supervised learning algorithm may be given a large data set of images of children labeled as "child", and images of the sky labeled as "sky". Once the model is trained, using these labeled inputs, it can then correctly label new images of children and skies it has never seen before with a large degree of accuracy. In related applications where generated content is involved, an AI detector can also be used to better understand whether outputs come from human input or machine learning systems.
Supervised learning algorithms can be used to learn complex patterns in historical data and to make predictions about future events. For example, a supervised learning algorithm can be fed a large data set of spam emails to build a model that can accurately and automatically label emails as spam depending on previous patterns it recognizes from its input data.
Machine Learning Using Unsupervised Learning
Unsupervised machine learning algorithms are used to find patterns in data without any prior knowledge of what those patterns might be. This is in contrast to supervised machine learning algorithms, which require a set of training data that already contains the desired patterns.
Unsupervised learning algorithms can be used to find patterns in data of all types, including text, images, and time series.
Some common unsupervised learning algorithms include clustering algorithms and neural networks.
Unsupervised Learning Example for Text Data
A company that receives thousands of customer feedback emails every month can use unsupervised learning to apply topic modeling algorithms to automatically discover the main themes or topics that are being discussed in these emails. This helps in understanding customer concerns and feedback without manually reading each email.
Unsupervised Learning Example for Image Data
In the field of medicine, unsupervised learning can be used to analyze medical images. For instance, K-Means Clustering can help in segmenting MRI images to identify different tissues or regions of interest, such as distinguishing between healthy tissue and potential tumors. This can assist doctors in diagnosis and treatment planning.
Machine Learning with Semi-supervised Learning
Semi-supervised machine learning algorithms use a combination of labeled and unlabeled data to train a model. The labeled data is used to train the model, while the unlabeled data is used to improve the model's accuracy.
This approach is more efficient than using only labeled data, because it can use the unlabeled data to fill in the gaps in the labeled data.
A semi-supervised machine learning algorithm is given a set of training data, along with a set of "unlabeled" data. The algorithm tries to learn the correct labels for the unlabeled data, based on the training data. This can be useful for problems where it is difficult to have a large amount of labeled data.
Machine Learning with K-nearest Neighbor
The k-nearest neighbor learning algorithm is a type of supervised learning algorithm that is used to predict the class of an unknown sample by finding the k closest training samples and then predicting the class of the unknown sample based on the majority class of the k closest training samples.
k is a positive integer that determines the class of the k nearest neighbors. In the case of k = 1, the object will be classified under the class of the single nearest neighbor. In the case of k = 2, the object will be classified under the class of the two nearest neighbors.
For example, you can give a k-nearest neighbor model the following input, where we have a number of squares and rectangles:
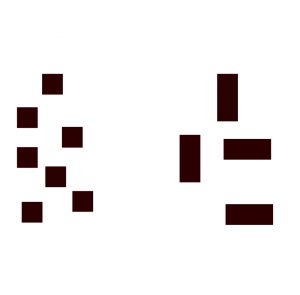
The data above belongs to two classes: the square class and the rectangle class.
Let's say that a new diamond object was added to this data:
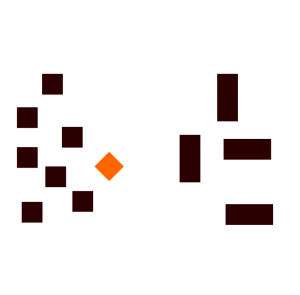
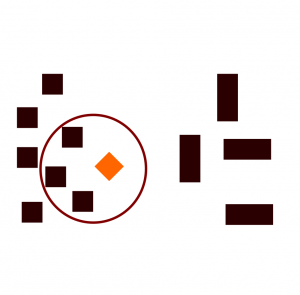
Setting k = 3, our model will determine the class of this new diamond object by trying to find the three nearest neighbors of the diamond object. And because the squares are nearer to the diamond, the algorithm will classify the diamond with the square class.
Machine Learning with Decision Tree Learning
A decision tree is a machine learning algorithm that is used to predict the outcome of a decision. The algorithm works by splitting the data set into two parts: the training set and the testing set. The training set is used to create the decision tree, and the testing set is used to test the accuracy of the decision tree. The decision tree is a series of if-then statements that predict the outcome of a decision.
For example, let's take a model that considers various conditions for whether to go out for a walk or not based on weather conditions:
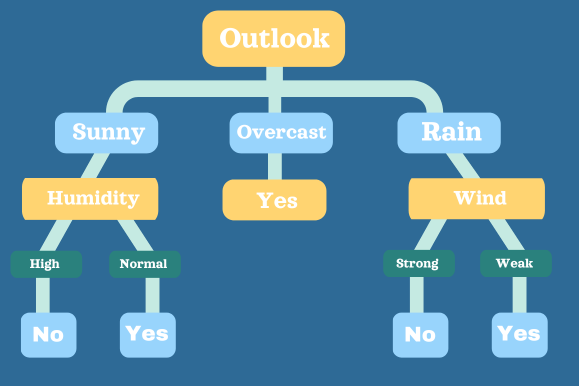
In the decision tree above, a decision is made by running the conditions through the decision tree. The ultimate decision is either Yes or No.
This basic decision tree demonstrates classifying a day's weather conditions. In more complex decision trees, the data set would have various features and complex conditions.
Machine Learning with Neural Networks
Neural Networks are a type of machine learning algorithm that are inspired by the brain. They are made up of a number of interconnected processing nodes, or neurons, that can learn to recognize patterns of input data.
Neural Networks are able to learn from data, and improve their performance over time. This makes them a powerful tool for solving complex problems, such as recognizing objects in images or recognizing speech.
Neural Networks are the basis of Deep Learning, which absorbs the most data and has been able to beat humans in some cognitive tasks. Deep learning techniques have significantly improved computer vision and speech recognition. A well-known example of a system that makes use of deep learning is OpenAI’s ChatGPT.
Conclusion
This introduction gives you a broad outline on machine learning and some of its current methods and approaches. To learn more about machine learning, check out the Machine Learning with Python course by Coursera.



